MSc Thesis: Training Set Optimisation for Linear B-Cell Epitope Prediction
Data Scientist / ML Research
Quick Links
On this page
MSc thesis optimizing training datasets and feature selection for Linear B-Cell Epitope prediction, benchmarking XGBoost vs neural networks with strong AUC/F1/MCC performance.
Visuals
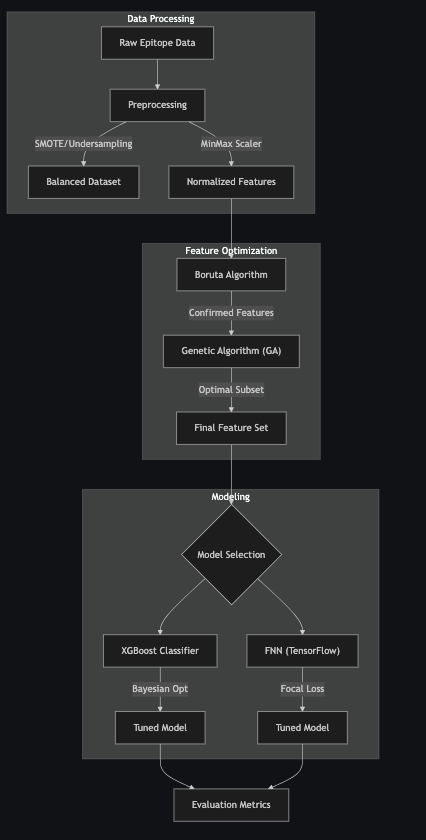
ML pipeline architecture
Click image to view full-size
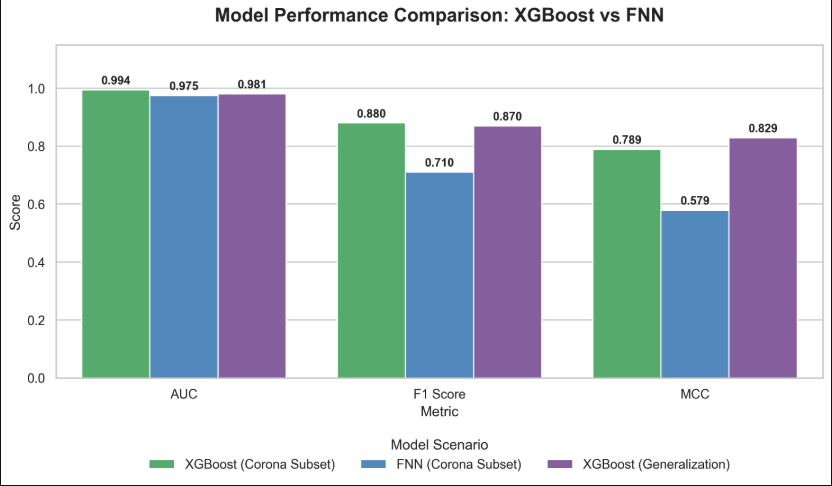
Model performance comparison
Click image to view full-size
Problem
Epitope prediction datasets are high-dimensional and imbalanced. Model performance depends on training-set composition and robust feature selection for generalization.
Solution
Built an ML pipeline comparing organism-specific training (Coronavirus subset) vs heterogeneous training. Reduced dimensionality (~400 physicochemical features) via Boruta + genetic algorithms, benchmarked XGBoost against feedforward neural networks (TensorFlow/Keras) using focal loss for class imbalance, applied SMOTE, and tuned with Bayesian optimization. Ran experiments on Azure ML for scalable compute and experiment tracking.
Key Results
- AUC-ROC: 0.994 (XGBoost Corona) | 0.981 (generalization)
- F1: 0.880 | MCC: 0.789–0.829
- Feature reduction: 393 → 88 features (-77.32%)
- Compared XGBoost vs FNN (TensorFlow/Keras) with Focal Loss
- Azure ML for scalable experiments + tracking